Bookmark is dead
The core concept of the internet is the hyperlink. Hyperlinks are responsible for navigation, juice spreading (the first version of Google SEO algorithm), sharing and storing content. But just like the prediction of Alan Toffler in the book Future Shock - lost content because of information overload — we are losing our links. Bookmark services are not enough. They have already failed, becoming weird, accumulating useless features, prioritizing recommendations rather than helping users collect and save links.

Delicous 2016: Ads everywhere
In the last few years, major bookmark services closed their doors. The browsers' bookmark system tries to organize links as folders and tags — but again, it’s an old model. Chrome's bookmark system has many usability problems, the main one being that you need to click three times to save one link in a specific folder.
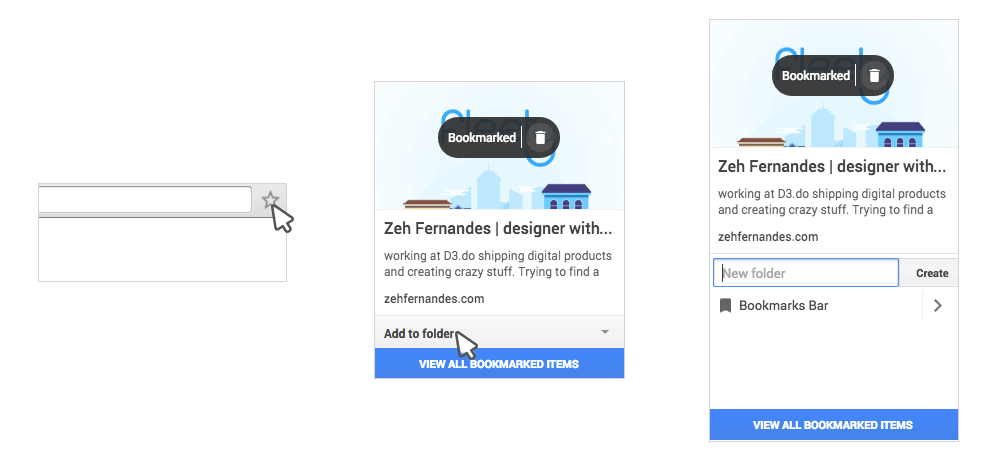
Chrome save link interface
So, why do we insist in this solution? How can we solve the anxiety of having to save links?
A new mental model
Let’s change the concept of storing links. The web is running towards the infinite, and we can’t stop the millions, trillions of links, images, videos and content. The pages you've visited are unique to you, it’s your individual path of hyperlinks. It’s almost like a fingerprint, so it’s impossible to have the same path and order of visited pages as anyone else. Let’s remove this anxiety around losing links and let’s make sure everything is saved in the infinite history of your browser
Of each hyperlink the user clicks on we record behavior, source, contents and bring natural search to our link path.