English Version: Cassio Oliveira
"Don't be evil", says the official letter of Google's Initial Public Offering in 2004. It is used as an internal motto to the present day. It acts as common sense for a company that, being so powerful, lives constantly on the brink of being corrupted to the dark side of the force. Star Wars or not, awareness is required, as this dark side is getting powerful amid the colorful empire named Google.
In 2013, the Edge magazine interviewed several people known for their intellectual contributions, asking them this question: "What should we be worried about?" Scientist and researcher W. Daniel Hillis 1 highlighted that we should worry about search engines becoming the arbiters of truth.
Hillis explains that previously any search would return web pages based on a sequence of letters matching the words searched. Now, Google searches semantically. When searching for "Museums of New York", it will look up for entities it recognizes as museums which are located inside the geographical region of New York. In order to do so, the computers performing the searching must know what a museum is, what New York is, and how these two are related. The computers must use this knowledge to make a judgment.
The problem becomes clearer when you change the keywords from "Museums of New York" to "Provinces of China". Is Taiwan a province? This is a controversial question and, in semantic search, the decisions are not based on statistics, but rather on world models. How about searching for "Dictators of the World?" The results, which include a list of famous dictators, are not just the judgment of whether someone is a dictator, but also an implicit judgment of choosing individual examples for the concept of a dictator. When building knowledge over concepts such as "Dictator" in the search engines, we are implicitly accepting a set of assumptions.


It is needed to question and monitor these models, for in the past, the significance was only in the human mind. Now, it is also in the mind of the engines that forward us information. The search bears an editorial point of view, and its results reflect this point of view. We can’t ignore the assumptions behind these results. The invisible judgments will frame our conscience. This article aims at introducing a discussion about how the Google monopoly is affecting the way we search for and receive information on the internet
Filter Bubble
Since 2009, each user has their own search results page from over 555 flags that Google uses to judge and sort results specifically for you. It basically analyzes what you seem to be interested in – things you or people similar to you do – and performs an extrapolation. They are prediction engines that constantly refine a theory about who you are and what you are going to do or want next. Together, they create an universe of data for each one of us. However, these predictions have a cost, which is discussed by Eli Parise 2 in his book, The Filter Bubble 3 using screenshots from Google searches done by two of his friends, Scott and Daniel. Both searched for the word Egypt; while Daniel got as first results the public demonstrations happening at the time, Scott’s results didn’t have any signs of them on the first page.

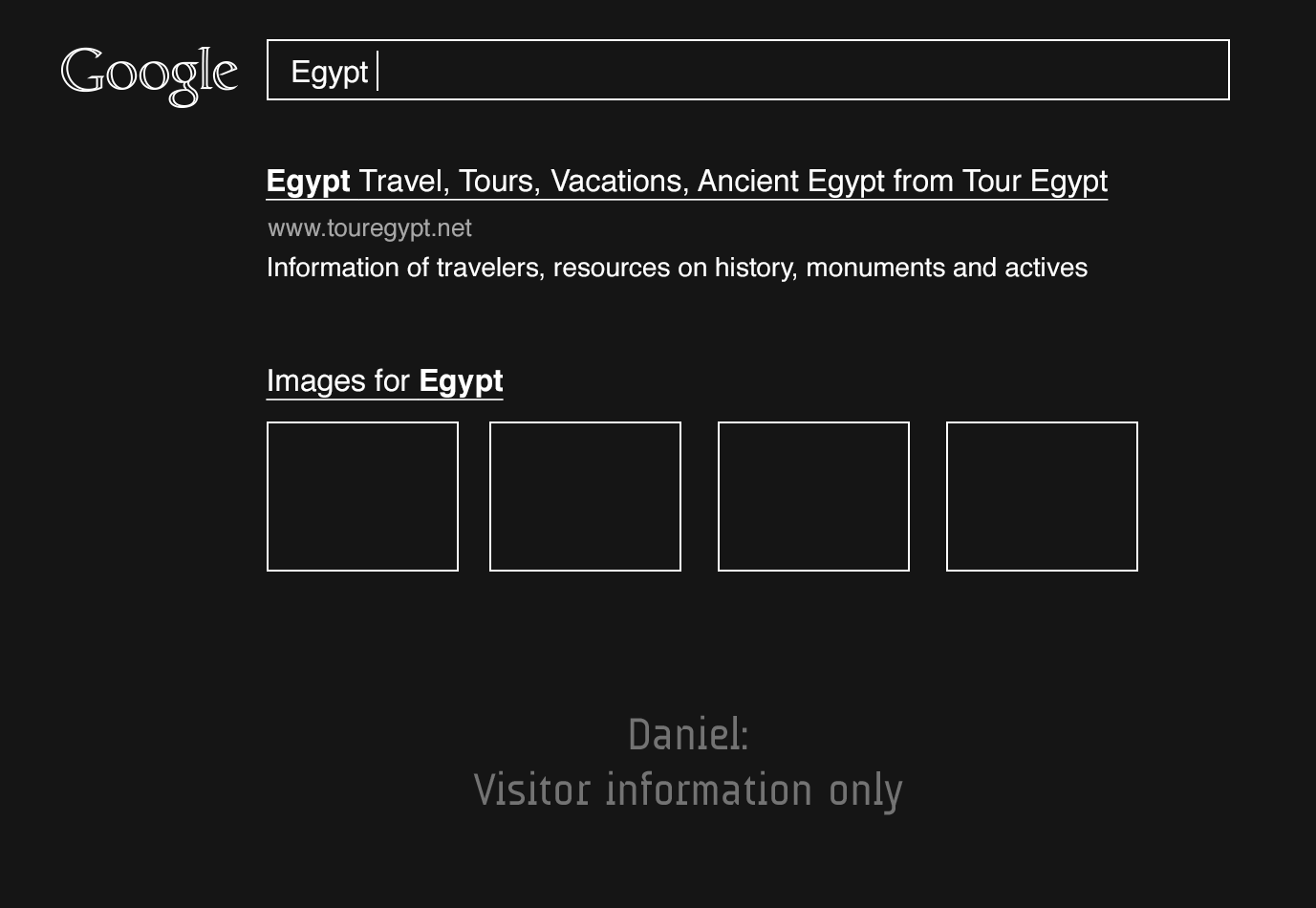 Source: Eli Parisier, 2011, original image
Source: Eli Parisier, 2011, original image
What is the decision behind judging that results concerning the protests were irrelevant to Daniel? Pariser argues about the filter bubble not being able to handle the complexity of human interests in a transparent way. The eternal dispute between what we want now and what we project for ourselves in the future.
(...) there are some movies that just sort of zip right up and out to our houses. They enter the queue, they just zip right out. (...) There's this epic struggle going on between our future aspirational selves and our more impulsive present selves. You know we all want to be someone who has watched Rashomon, but right now we want to watch Ace Ventura for the fourth time.”
The search results invisibly limit its contents, creating a bubble that prevents us from seeing what’s out of it. “Because personalized filters usually have no Zoom Out function, it’s easy to lose your bearings, to believe the world is a narrow island when in fact it’s an immense, varied continent.”
In his 2010 TED: Listening to Global Voices talk, Zuckerman 4 remarks on how difficult it is to find online content about creative production from overseas:
“If I walk into a store in the United States, it's very, very easy for me to buy water that's bottled in Fiji, shipped at great expense to the United States; it's surprisingly hard for me to see a Fijian feature film. It's really difficult for me to listen to Fijian music.”
The bubble generates a confimation bias; people prefer information that supports their beliefs and expectations, regardless of their truth of falsity 5, as it displays only the main, superficial interests of the user, going against the promotion of diversity of ideas.
Privacy and Transparency
The personalization algorithm is based on the concept of Big Data 6 to make decisions, that is, it requires the largest amount of data possible. This results in storing and tracking any information about the user. Websites such as MSN, Yahoo, and CNN install an average of 64 cookies in order to obtain information about the user online behavior.
The Dont Track Us site illustrates in a step-by-step how this monitoring is done and how it is used: when you Google search anything and then click on one of the results, the searched terms are sent to Google along with your IP address, location, browser etc. forming your own online identity. These websites often display ads from third parties, which use the online identity to create a profile for the user (age, gender, interests, physical characteristics) and then pursue him/her with related ads everywhere.
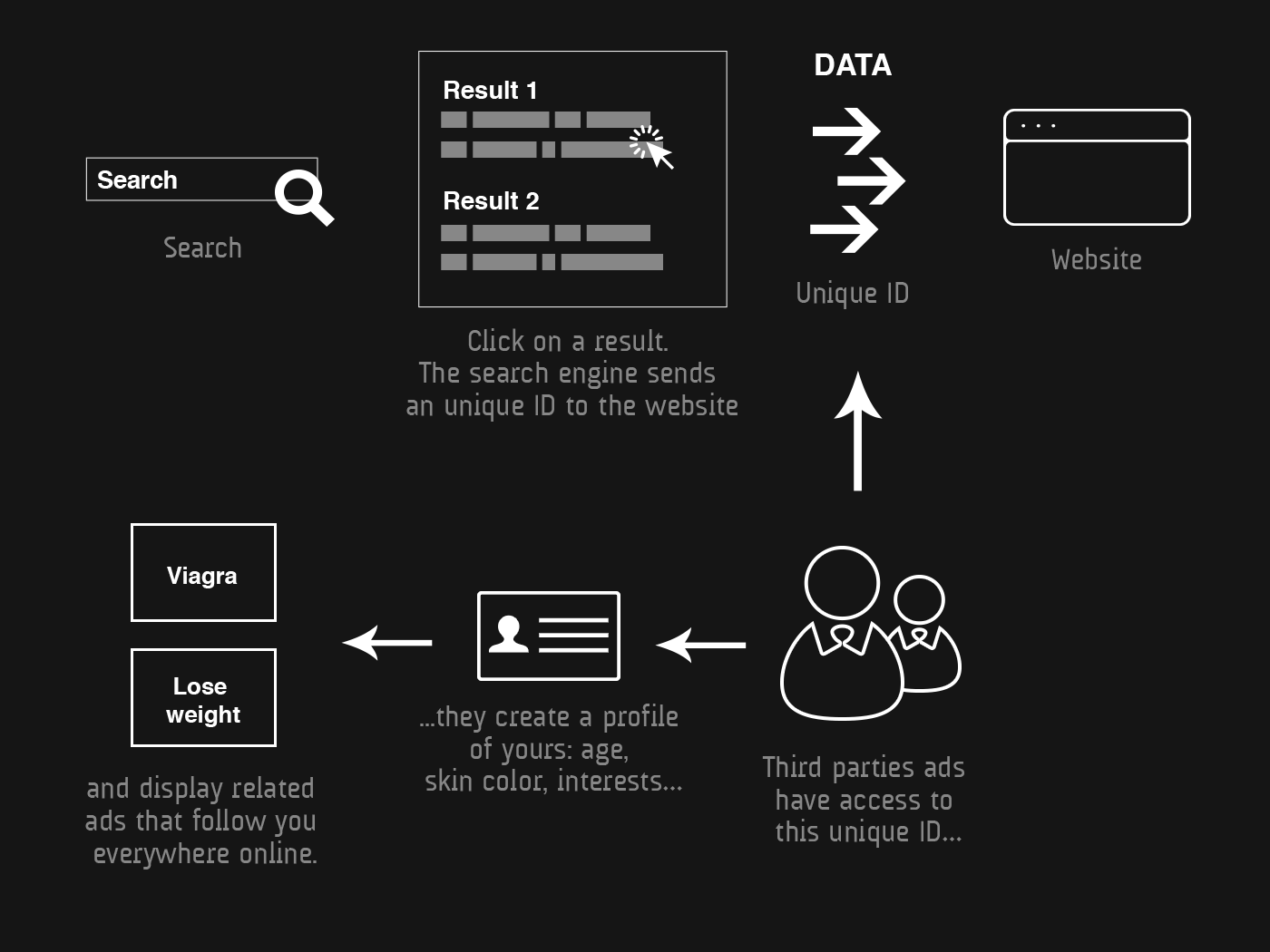
This information is not limited to advertisement. Your profile can be sold in order to offer higher prices, an example being the Orbitz hotel chain (which displays more expensive hotels to Apple users); or to discover if someone is a potential buyer, as told by The Washington Street Journal; or even to sell the data to database companies, such as TargusInfo, that prides itself in offering more than 62 million attributes in real time every year, or Rubicon, that claims to have more than half a billion users in their database.
The Financial Times website published an interactive calculator to find out how much your personal information is valued. The value of personalization goes beyond, since Google keeps your search history, which can be legally requested by justice courts and governments, as claimed by Readwrite. In 2010, Brazil made 3663 appeals to access online data and asked for 291 sites to be brought down. Chris Palmer, Electronic Frontier Foundation tech director, commented on this: "You're getting a free service, and the cost is information about you."
Behavior Induction
In a 2010 paper published in the Scientific American journal, Tim Berners-Lee 7 warned about companies developing ever more “closed” products and “data islands”. The internet was becoming increasingly fragmented and less universal. That’s going the opposite direction of the what was initially envisioned for the web, which was born to share knowledge and the democratic premise of equal access to information to all. A company and a single individual would have the same power of expression.
Search engines are becoming huge. Proof of this, is the impossibility to measure the impact of the alterations in the Google algorithm. “The team tweaks and tunes, they don’t really know what works or why it works, they just look at the result.” Lanier 8 questions the relevance of the first links resulted of searches in these engines:
"When you look something up in a search engine, just keep flipping through results until you find the first one written by a particular person with a connection to the topic. If you do this, you'll generally find that for most topics, the Wikipedia entry is the first URL returned by search engines but not necessarily the best URL available."
He attested to the fact arguing about the webpages that seldom appear as first results, such as ThinkQuest, an initiative that happened in the early days of World World Web. Teams of high school students would competed for scholarships, designing websites with explanations about a myriad of concepts and ideas from various areas. The task included simulations, interactive games and other tools, in search for new ways of presenting complex knowledge, such as mathematics.
Joachims made an experiment with the vertical display of search engines by reversing the order of the results, proving that the participants were influenced by the order of presentation, since the number of hits in the first result was significantly larger than the attention deserved. Morville, in his book Search Patterns, 9 says that the first and second results receive 80% of attention. The vertical approach suggests to the user the idea of a single result that fully answers the question, enclosing possibilities and preventing alternative realization.
Monopoly
In a meeting with analysts, as he left his job at Microsoft, Steve Ballmer accused Google of monopolization. His statement was yet another amid the list of accusations the company had already received, which are mainly focused on market control and cartelization. Google has been previously prosecuted and investigated by the European Union, suspect of blocking competitors in search results.
Tim Wu describes the cycle of every information system in his book, The Master Switch 10. It begins wide open, slowly closing as it’s consolidated. Wu exemplifies the cycle with the histories of telecommunications giant monopolist Bell AT&T, the founder of Hollywood entertainment industry, and the rise of cable TV. Ultimately, he points to the cycle internet is going through, with companies such as Google, Facebook, and Apple in charge.
Recently, Gizmodo published a list of the services Google provides: productivity software, publishing software, operating systems, mobile phones, laptops, maps, online videos, shopping, payments, social networks, messaging, telecommunications, futuristic technologies, health, and advertisement. Every service uses the influence of another one as competitive advantage. An example of this is the increased functionality of Google’s search engine if you are using their browser, Chrome. This market domination is yet extended. In an article in his blog, Harris analyzed the webpage containing the search results and concluded that only 13% of it is used by the organic search - rresults collected directly by the algorithm – when he searched for the term “auto mechanic” while logged in his account. The rest of the page is filled with other Google products: 29% Adwords, 14% navigation bar and Google+ notifications, and 7% Google Maps.
 Source: Herris Tutpress original image
Source: Herris Tutpress original image
The percentage occupied by the organic search is even smaller if using a mobile device. Harris performs the same experiment by searching for “Italian food” in his iPhone. He had to scroll down four times before reaching the organic search results. If considering that 29% of the page belongs to Adwords, Google’s advertising branch, and that, in 2011, the company had 43,5% of all profits related to online advertising 11, one can predict a future when, in order to enter the Google world, you will have to pay.
Alternative Search Engines
The continuous use of these services without questioning them is to allow an invisible robotic curation that creates a false sense of neutrality. It insulates content and shuts the dissemination of cultural production of other countries, becoming something ordinary and stable.
As Tim Wu, Eli Pariser, and others fighting for Open Web, we must always be aware and well informed about the intentions of companies, and never stop having multiple options for any service.









